
The first time I watched a reasoning model work, I remember thinking it felt almost rude to interrupt. The little thinking indicator just sat there, ticking, while the model worked through some math problem in a way that looked, for the first time, like it was actually working through it. Not pretending. Not pattern-matching at speed. Just thinking, slowly, in front of me. And it makes me wonder if we've fully reckoned with how strange that is.
For most of the last few years, my mental model of an LLM was an extremely confident party guest. Ask a question, get an answer immediately, sometimes brilliant, sometimes wildly wrong, but always delivered in the same self-assured tone. Reasoning models broke that for me. They pause. They double back. They write things like "wait, let me check that again." It's the first time the texture of the output has felt different from the underlying thing.
What actually changed
The honest version of the story is that nothing magical happened. We didn't unlock a new architecture or invent a new substrate. What we did was notice something quieter: if you ask a regular model to think out loud before it answers, it gets better at hard problems. People started calling this chain-of-thought, and for a while it was a prompting trick. You'd write "let's think step by step" at the bottom of your prompt and watch your accuracy on math and logic tasks jump.
What reasoning models did was take that trick and bake it into the model itself. Instead of you having to ask for the thinking, the model just does the thinking by default. It reasons before it speaks. The thought process isn't a clever prompt anymore. It's part of the model's natural behaviour. That sounds like a small shift, but I keep coming back to it because it's not.
Slow thinking, in software
The framing that made the most sense to me is the System 1 / System 2 split from psychology. System 1 is fast and intuitive — what you use to recognise a face or finish a sentence. System 2 is slow and deliberate — what you use to do long division or plan a trip. Old LLMs were almost pure System 1. They produced answers the way you produce the next word in a familiar sentence: instantly, fluently, without much examining.
Reasoning models are the closest thing we've had to System 2 in a language model. And it makes me wonder what we lost by spending so many years optimising for speed. Some problems just need someone to sit with them for a minute. We had built a generation of AI tools that physically couldn't do that, and we didn't quite notice because we'd rebranded the limitation as a feature.

How they actually got there
I won't pretend the training process is intuitive, but the part that stuck with me is how much of it ended up bootstrapping itself. The early reasoning datasets were painstakingly written by humans, step by step. That obviously didn't scale. So researchers did the only thing that ever works in this field: they let the models generate their own training data, then trained newer models on it, then used those newer models to generate even better data, and so on.
It's a very modern kind of loop. The student becomes the teacher becomes the student again. The DeepSeek R1 work was the most public example of this, where reinforcement learning alone, without any traditional fine-tuning, was enough to produce reasoning behaviour from scratch. I find that genuinely surprising. It suggests the capacity to reason was already sitting there in the base model, latent, waiting for someone to give it permission.
What they're good for, and what they're not
The temptation, once you have a hammer this shiny, is to swing it at everything. I've done it. I've watched other people do it. We are all going to spend the next year burning compute by asking a reasoning model to summarise a one-paragraph email.
The honest answer is that reasoning models are great when there is something to actually reason about. Multi-step math. Code with non-obvious bugs. Planning problems with real constraints. Anywhere the answer requires you to hold three things in your head at once and check them against each other. They are noticeably worse — slower, more expensive, more verbose — for things that don't need that. Translation. Tone changes. Quick lookups. The kind of work where the answer is right there and the model just has to fetch it.
Reasoning models are the closest thing we've had to System 2 in a language model. The question I keep asking is what we missed by spending so long optimising for System 1.
How prompting changed
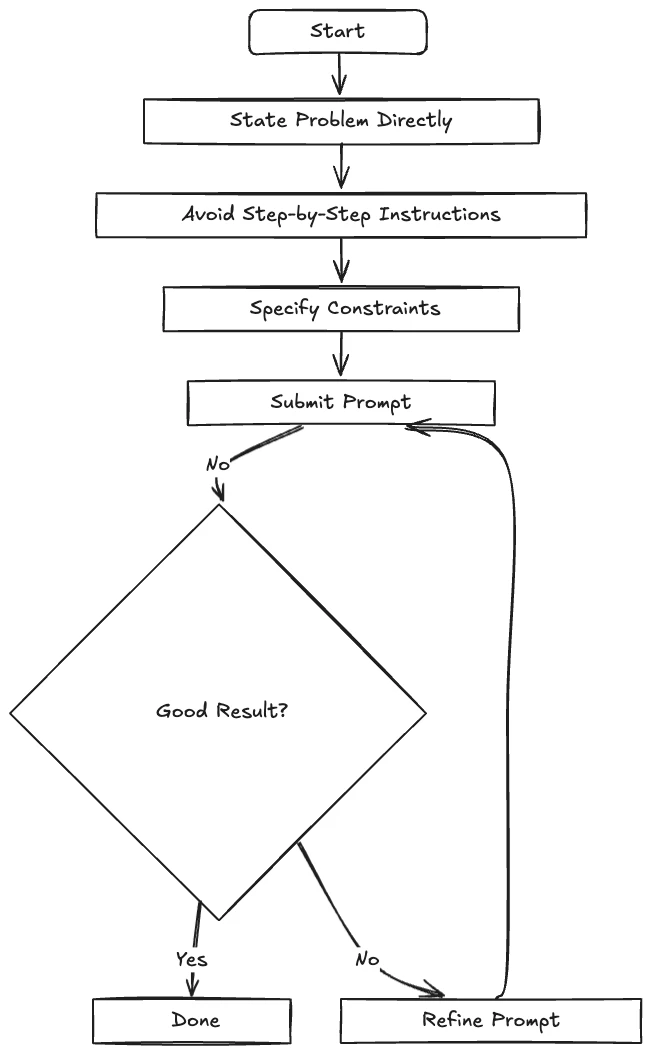
The thing nobody warns you about is that your old prompting habits actively hurt you with these models. The long, careful, "first do this, then do that, and explain your reasoning" prompts that used to squeeze better answers out of GPT-4 will make a reasoning model worse. It already knows how to think. Telling it to think is like backseat-driving someone who's already on the right road. They get annoyed and the route gets worse.
What works instead is almost embarrassingly simple. State the goal. Give the constraints. Get out of the way. The shorter the prompt, the better the result, as long as it's clear. After years of treating prompts as elaborate instructions, it's a strange feeling to write three lines and watch a model do its best work. It feels like under-trying. It mostly isn't.
What I'm sitting with
I keep thinking about how quiet this revolution has been. There was no big architectural unveiling. No new modality. Just a shift in what the model is allowed to do before it speaks. And yet the products built on top of reasoning models feel different in a way that's hard to put my finger on. They feel less like autocomplete and more like a colleague who actually paused to consider your question.
I don't think we know yet what that's going to mean for the rest of software. But it's making me rethink the assumption I'd been carrying around for years: that the fastest answer is the best one. With reasoning models, the slowest one usually is. That's a small idea with very large consequences, and I suspect we're going to be unpacking it for a while.